شرح مساله
جدولی را متصور شوید که تنها یک ستون عددی متوالی (کلید اصلی است) دارد و داده های روبرو در آن ذخیره شده اند: T = {14, 15, 16, 21, 22, 25, 26, 27, 28, 35} <-- the set؛ اعدادی در این بین جا افتاده اند که به آنها Gap گفته می شود. این فضاهای هرز رشته ی اعداد را از همدیگر قطع و جدا کرده اند و به اصطلاح جزیره هایی (Islands) را بوجود آورده اند. مجموعه T دارای چهار چزیره است که بصورت زیر مجموعه آنها را مشخص کرده ام:
T1 = {14, 15, 16}, T2 = {21, 22}, T3 = {25, 26, 27, 28}, T4 = {35}
T = T1 U T2 U T3 U T4
برای روشنی هر چه تمام تر موضوع تصویری را آماده کرده ام که خود گویاست:
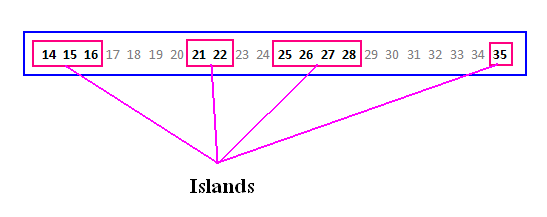
اگر کادر آبی رنگ را اقیانوس در نظر بگیریم. کادرهای قرمز رنگ داخلی جزایر ما محسوب می شوند. جزایر با فضاهایی که گپ ها (اعداد خاکستری رنگ) بوجود آمده اند از هم تفکیک می شوند. و حالا به این تصویر نگاه کنید:
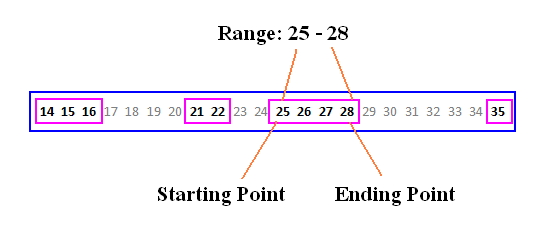
هدف ما شناسایی جزایر و پیدا کردن نقاط شروع و پایان آنهاست. این مساله یک موضوع کاملا کاربردی است که در مقاله ی "حذف کاراکترهای تکراری کنار هم" در روش grouping , ranking از آن استفاده شده است.
آماده سازی
حالا بعد از اینکه موضوع مشخص شد نیاز به یک جدول و یکسری داده های آزمایشی داریم تا بعدا برای تست راه حل ها از آنها استفاده کنیم.
CREATE TABLE SeqValue
(Number INTEGER NOT NULL PRIMARY KEY);
INSERT INTO SeqValue VALUES
(14), (15), (16), --Island 1
(21), (22), --Island 2
(25), (26), (27), (28), --Island 3
(35); --Island 4
نتیجه مورد نظر ما این است:
starting_point ending_point
-------------- ------------
14 16
21 22
25 28
35 35
راه حلها
روش اول: در این روش ابتدا نقاط پایان (ending point) هر جزیره را بدست آورده سپس در ماده SELECT توسط Correlated Subquery نزدیک ترین نقطه ی شروع به نقطه پایان که کوچکتر از نقطه پایان است را بعنوان نقطه شروع (starting point) بدست می آوریم. یا می توانیم ابتدا نقاط شروع را پیدا کرده و نزدیک ترین نقطه پایان که بزرگتر از نقطه شروع است را بعنوان نقطه پایان بدست آوریم. برای بدست آوردن نقاط شروع یا پایان از یک مفهوم خیلی ساده استفاده می کنیم؛ به زبان ساده برای نقطه پایان، هنگامی که وجود نداشته باشد عددی که یک مقدار از عدد جاری بیشتر باشد آنگاه عدد جاری نقطه پایان جزیره را مشخص می کند.
در ادامه برای این روش یک جفت راه حل ارائه داده ام یعنی با کمک NOT EXISTS() Predicate و دیگری nonstarndard table operator OUTER APPLY.
-- [NOT] EXISTS() Version
SELECT (SELECT MAX(Number)
FROM SeqValue t1
WHERE NOT EXISTS
(SELECT 1
FROM SeqValue
WHERE Number = t1.Number - 1)
AND Number <= t.Number) AS starting_point,
number as ending_point
FROM SeqValue t
WHERE NOT EXISTS
(SELECT 1
FROM SeqValue
WHERE Number = t.Number + 1);
-- APPLY Version I
SELECT (SELECT MAX(Number)
FROM SeqValue S1
OUTER APPLY
(
SELECT 1
FROM SeqValue S2
WHERE S2.Number = S1.Number - 1
) AS D(i)
WHERE D.i IS NULL
AND S1.Number <= S.Number) AS starting_point,
S.Number AS ending_point
FROM SeqValue AS S
OUTER APPLY
(
SELECT 1
FROM SeqValue S2
WHERE S2.Number = S.Number + 1
) AS D(i)
WHERE D.i IS NULL;
-- APPLY Version II
SELECT T.starting_point,
S.Number AS ending_point
FROM SeqValue AS S
OUTER APPLY
(
SELECT 1
FROM SeqValue S2
WHERE S2.Number = S.Number + 1
) AS D(i)
CROSS APPLY
(SELECT MAX(Number)
FROM SeqValue S1
OUTER APPLY
(
SELECT 1
FROM SeqValue S2
WHERE S2.Number = S1.Number - 1
) AS D(i)
WHERE D.i IS NULL
AND S1.Number <= S.Number) T(starting_point)
WHERE D.i IS NULL;
راه حل دوم: در این روش از مفهوم "Grouping Factor" استفاده می شود. به عبارت دیگر اگر به هر جزیره یک شناسه منحصر بفرد بدهیم می توانیم بر اساس این شناسه گروه بندی کرده و در نهایت با کمک دو تابع Minimum و Maximum نقاط شروع و پایان هر جزیره را بدست آوریم. پس یک روش این است که برای هر عنصر از جزیره نقطه پایان و یا نقطه شروع را بدست آوریم. و بعد با کمک همین ستون بدست آمده گروه بندی انجام دهیم. من از نقطه شروع برای عامل فاکتور بندی استفاده کردم.
ابتدا برای جزایر شناسه تولید می کنیم:
Number grp_factor
----------- -----------
14 14
15 14
16 14
21 21
22 21
25 25
26 25
27 25
28 25
35 35
سپس نتیجه ی حاصل را بر اساس شناسه ی تولید شده گروه بندی می کنیم؛ در ادامه برای این راه حل دو روش یکی Correlated Scalar Subquery و دیگری Nonstandard table operator APPLY استفاده شده است.
SELECT MIN(Number) AS starting_point,
MAX(Number) AS ending_point
FROM (
SELECT Number,
(SELECT MAX(B.Number)
FROM SeqValue AS B
WHERE B.Number <= A.Number
AND NOT EXISTS
(SELECT *
FROM SeqValue AS C
WHERE C.Number = B.Number - 1)) AS grp_factor
FROM SeqValue AS A
) AS D
GROUP BY D.grp_factor;
APPLY:
SELECT MIN(Number) AS starting_point,
MAX(Number) AS ending_point
FROM SeqValue A
CROSS APPLY (SELECT MAX(B.Number)
FROM SeqValue AS B
OUTER APPLY (SELECT 1
FROM SeqValue AS C
WHERE C.Number = B.Number - 1) D(i)
WHERE B.Number <= A.Number
AND D.i IS NULL
) AS D(grp_factor)
GROUP BY D.grp_factor;
روش سوم: اگر در دو عبارت جدولی بطور مستقل نقاط شروع و نقاط پایان را بدست آوریم سپس می توانیم نقاط مرتبط را با همدیگر JOIN کنیم و نتیجه مطلوب را بدست آوریم.
;WITH StartingPoints AS
(
SELECT number, ROW_NUMBER() OVER(ORDER BY number) AS rownum
FROM SeqValue AS A
WHERE NOT EXISTS
(SELECT *
FROM SeqValue AS B
WHERE B.number = A.number - 1)
),
EndingPoints AS
(
SELECT number, ROW_NUMBER() OVER(ORDER BY number) AS rownum
FROM SeqValue AS A
WHERE NOT EXISTS
(SELECT *
FROM SeqValue AS B
WHERE B.number = A.number + 1)
)
SELECT S.number AS start_range, E.number AS end_range
FROM StartingPoints AS S
JOIN EndingPoints AS E
ON E.rownum = S.rownum;
روش چهارم: برای بدست آوردن یک عامل برای گروه بندی می توانیم از تفاضل بین اعداد متوالی تولید کرده با اعداد متوالی موجود در جدول استفاده کنیم. داده های روبرو را فرض کنید: T = {19, 20, 21, 22} <-- Data حالا برای مقادیر موجود اعداد ترتیبی تولید می کنیم، یعنی T = {(19, 1), (20, 2), (21, 3), (22, 4)} <-- Data حالا همانطوری که مشخص هست چون هر دو گروه از اعداد به صورت کاملا مرتبی افزایش پیدا می کنند در نتیجه اختلاف بین آنها نیز یک عدد ثابت (18) است. از مقدار حاصل از تفاضل می توانیم به عنوان شناسه ای برای هر جزیره استفاده کنیم.
وظیفه تولید اعداد متوالی و ترتیبی را به عهده ROW_NUMBER می سپاریم:
SELECT *, Number - ROW_NUMBER() OVER(ORDER BY Number) AS rec_id
FROM SeqValue
/*
Number rec_id
----------- --------------------
14 13
15 13
16 13
21 17
22 17
25 19
26 19
27 19
28 19
35 25
*/
سپس بعد از گروه بندی مینیمم و ماکسیمم را بدست میاوریم:
SELECT MIN(Number) AS start_range,
MAX(Number) AS end_range
FROM
(
SELECT *, Number - ROW_NUMBER() OVER(ORDER BY Number) AS rec_id
FROM SeqValue
) AS D
GROUP BY rec_id;