مقدمه
Cross Tabulations یا بطور خلاصه Crosstabs (که به PivotTable نیز شناخته می شود) یک گزارش آماری رایج است. خیلی از spreadsheets هایی مثل Excel می توانند نتایج پرس و جوهای SQL را بارگذاری کنند و عمل Crosstab را روی آن انجام دهند. شرکت ماکروسافت در MS SQL Server 2005 برای اولین بار عملگر جدولی غیر استانداردی به نام PIVOT را برای این منظور معرفی کرد(البته در کنار عملگر UNPIVOT). در این مقاله به راه حل ها یا روشهای موثری برای تولید Crosstab که همگی قابل استفاده در تمام نسخه های SQL Server و مطابق با استانداردهای زبان مجموعه گرای SQL اند را خواهم پرداخت. و امید وارم در مقالات بعدی فرصتی ایجاد شود تا به عملگر جدولی غیر استاندارد PIVOT در SQL Server 2005 و Dynamic Pivot بپردازم.
کدها تست و اجرا شده اند و syntax مربوط به درج داده ها تنها در SQL Server 2008 پشتیبانی می شوند.
(عملگرهایی که در ماده ی FROM استفاده می شوند را عملگر های جدولی گویند. تنها یک عملگر جدولی استاندارد وجود دارد آن هم JOIN می باشد. ولی در SQL Server عملگرهای جدولی دیگری معرفی شده اند که همگی غیر استاندارد هستند از جمله APPLY و PIVOT)
محیط عملیاتی
فرض کنید جدولی به نام فروش ( sales) ایجاد کرده ایم که وضعیت فروش هر محصول (قیمت و تعداد فروش) را در هر سال مشخص می کند و جدولی دیگر با نام محصولات (products) مشخصات هر محصول را در بر می گیرد (مثل نام، وزن و...). ساختار جداول همراه با انتشار داده های آزمایشی به این شکل می باشند.
BEGIN TRAN;
CREATE TABLE Products
(product_name VARCHAR(15) NOT NULL
PRIMARY KEY CLUSTERED,
[weight] INTEGER NOT NULL,
CHECK (weight > 0));
GO
INSERT INTO Products (product_name, [weight])
VALUES ('P1', 5),
('P2', 25),
('P3', 12),
('P4', 1);
GO
CREATE TABLE Sales
(product_name VARCHAR(15) NOT NULL
REFERENCES Products (product_name),
product_price DECIMAL(5,2) NOT NULL,
qty INTEGER NOT NULL,
sales_year INTEGER NOT NULL);
GO
INSERT Sales (product_name, product_price, qty, sales_year)
VALUES('P1', 85.5, 4, 1990),
('P1', 100, 10, 1990),
('P1', 121, 7, 1991),
('P2', 50, 15, 1993),
('P2', 85.5, 13, 1994),
('P3', 12, 1, 1990),
('P3', 7, 25, 1991),
('P3', 7.5, 14, 1991),
('P3', 5, 3, 1993);
GO
COMMIT TRAN
تصویر داده های موجود در جداول (که با یکدیگر JOIN شده اند):
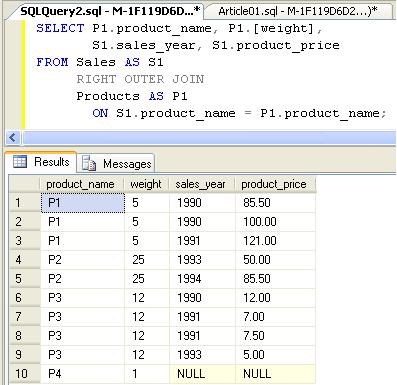
گزارشی که پس از پردازش داده های فوق انتظارش می رود:
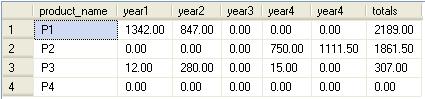
همانطوری که در تصویر فوق نتیجه مورد نظر مشاهده می شود، برای هر محصول در جدول Product ما جمع کل فروش را نیاز داریم (totals) البته در کنار آن تفکیک فروش در سال های مختلف که در مثال فوق جمع کل فروش محصول در سال 1990 در ستون year1 و جمع فروش محصول در سال 1991 برای ستون year2 و همینطور به ترتیب تا سال 1994 برای ستون year4.
بطور مثال محصول P4 اصلا هیچ فروشی نداشته است. و محصول P3 در سال 1990 یک نمونه ی آن با مبلغ 12 واحد به فروش رسیده است و ...
برای تولید Crosstab راه حل های متعددی وجود دارد که استفاده از عبارت CASE یکی از بهترین، ساده ترین و شناخته ترین روش ها است. آقای Joe Celko در کتاب معروف خود با نام JOE CELKO'S SQL FOR SMARTIES: Advanced SQL Programming به روش های استاندارد تولید Crosstab پرداخته است. که در ادامه آنها را مورد بررسی قرار خواهم داد. در بخش های بعدی این مقاله بعد از معرفی PIVOT به مقایسه ی عملکرد (Performance) دو تا از بهترین روش ها در یک سناریوی خاص می پردازم.
اشاره به این نکته ضروری است که برخی از روشهای موجود در این مقاله موثر (Efficient) و کاربردی (Practical) نخواهند بود و تنها برای تکامل یافتن و معرفی تمام راه حل ها پیشنهاد شده اند. مثل روش subquery و outer apply.
انواع روشهای تولید crosstab (بدون روش های ویژه ی SQL Server)
* Matrix Table
* Multiple Outer Joins
* Case Expression
* Subquery
* David Rozenshtein Method
Crosstab با OUTER JOINS
اگر در یکسری جداول موقت یا VIEW و یا عبارت های جدولی جمع کل فروش محصولات را در سال های مختلف بدست آوریم سپس می توانیم آن جداول را با یکدیگر اتصال داده و جمع فروش محصولات در سالهای مختلف را در یک جدول به نمایش در آوریم. و برای اینکه ممکن است یک محصول در تمام سالها فروش نداشته باشد از اتصال خارجی استفاده می کنیم. در اتصال خارجی مقادیری که match نشدن با مقدار NULL نمایش داده می شود در این حالت می توانیم از تابع COALESCE برای تبدیل مقادیر NULL به عدد صفر استفاده کنیم.
من در این مورد از CTE یا Common Table Expression استفاده کرده ام (شما می توانید از Derived table یا حتی VIEW استفاده کنید) از CTE استفاده کردم تا کپسوله سازی اتفاق افتد و امکان درک Query به حد اکثر ممکنه برسد. ممکن است خیلی از کاربران از CTE بندرت استفاده کرده باشند یا حتی آشنا نباشد ولی CTE یک جایگزین بسیار مناسبی برای Derived Table است. زمانی که چند عبارت جدولی پشت سرهم تعریف می شوند بایستی از کاراکتر کاما (comma) برای تفکیک جداول استفاده شود.
;WITH C1 AS
(SELECT product_name,
SUM(qty * product_price) AS year1
FROM Sales
WHERE sales_year = 1990
GROUP BY product_name),
C2 AS
(SELECT product_name,
SUM(qty * product_price) AS year2
FROM Sales
WHERE sales_year = 1991
GROUP BY product_name),
C3 AS
(SELECT product_name,
SUM(qty * product_price) AS year3
FROM Sales
WHERE sales_year = 1992
GROUP BY product_name),
C4 AS
(SELECT product_name,
SUM(qty * product_price) AS year4
FROM Sales
WHERE sales_year = 1993
GROUP BY product_name),
C5 AS
(SELECT product_name,
SUM(qty * product_price) AS year5
FROM Sales
WHERE sales_year = 1994
GROUP BY product_name),
totals AS
(SELECT product_name,
SUM(qty * product_price) AS totals
FROM Sales
GROUP BY product_name)
SELECT P1.product_name,
COALESCE(year1, 0) AS year1,
COALESCE(year2, 0) AS year2,
COALESCE(year3, 0) AS year3,
COALESCE(year4, 0) AS year4,
COALESCE(year5, 0) AS year5,
COALESCE(totals, 0) AS totals
FROM Products P1
LEFT OUTER JOIN C1
ON P1.product_name = C1.product_name
LEFT OUTER JOIN C2
ON P1.product_name = C2.product_name
LEFT OUTER JOIN C3
ON P1.product_name = C3.product_name
LEFT OUTER JOIN C4
ON P1.product_name = C4.product_name
LEFT OUTER JOIN C5
ON P1.product_name = C5.product_name
LEFT OUTER JOIN totals
ON P1.product_name = totals.product_name;
نگران زیادی تعداد خطوط Query نباشید! این روش یکی از سریع ترین روش های ممکن برای حل این مساله است. به دلیل اینکه قابلیت استفاده از ایندکس مطلوب را دارا است.
Crosstab با کمک Correlated Scalar Subqueries
Subquery و مخصصوصا پرس و جوهایی تودرتوی وابسته (correlated nested query) یکی از قابلیت هایی است که به زبان SQL قدرت و انعطاف پذیری فوق العاده ای داده است. و اما متاسفانه جدا از مرحله ی نظری در بعد عملی بایستی داده ها از جداول استخراج شوند و query هایی می توانند سرعت بالاتری داشته باشد که نیاز کمتری به خواندن داده ها از روی حافظه ی مقیم در cache یا دیسک سخت (hard disk) داشته باشند. به هر حال این دیدگاه و سبک نوشتن کوئری ها از نظر تئوری و زبان شیرین SQL جایگاه ویژه ای دارد.
یکی از مزایای این سبک این است که نیاز ما را به به هر نوع اتصال (داخلی یا خارجی) برطرف می کند.
این روش بر خلاف سادگی بسیاری که دارد (تنها از سه ماده ی SELECT و FROM و WHERE استفاده شده است!) سرعت بسیار نامناسب و غیر کارامدی داشته و همچنین هزینه ی Read بالایی هم دارد.
توجه داشته باشید که از علامت تساوی (=) برای دادن نام مستعار استفاده شده است که ممکن است در نرم افزارهایی غیر از SQL Server مورد استفاده قرار نگیرد. شما می توانید از AS برای این منظور استفاده کنید.
SELECT product_name,
year1 = COALESCE((SELECT SUM(qty * product_price)
FROM Sales
WHERE sales_year = 1990
AND product_name = P.product_name), 0),
year2 = COALESCE((SELECT SUM(qty * product_price)
FROM Sales
WHERE sales_year = 1991
AND product_name = P.product_name), 0),
year3 = COALESCE((SELECT SUM(qty * product_price)
FROM Sales
WHERE sales_year = 1992
AND product_name = P.product_name), 0),
year4 = COALESCE((SELECT SUM(qty * product_price)
FROM Sales
WHERE sales_year = 1993
AND product_name = P.product_name), 0),
year5 = COALESCE((SELECT SUM(qty * product_price)
FROM Sales
WHERE sales_year = 1994
AND product_name = P.product_name), 0),
totals = COALESCE((SELECT SUM(qty * product_price)
FROM Sales
WHERE product_name=P.product_name), 0)
FROM Products P;
Crosstab با CASE Expression
عبارت CASE در SELECT Statement یک قابلیت فوق العاده موثری را بوجود آورده است. از CASE حتی در داخل توابع تجمعی مثل MAX و SUM می توانیم استفاده کنیم.
یکی از مزیت های این روش بسیار کم بودن هزینه ی I/O آن است و هچنین خوانایی (readability) آن بسیار بالا بوده و بسادگی می توان آن را گسترش داده یا اصلاح کرد.
SELECT P1.product_name,
year1 = SUM(CASE WHEN sales_year = 1990 THEN qty * product_price ELSE 0 END),
year2 = SUM(CASE WHEN sales_year = 1991 THEN qty * product_price ELSE 0 END),
year3 = SUM(CASE WHEN sales_year = 1992 THEN qty * product_price ELSE 0 END),
year4 = SUM(CASE WHEN sales_year = 1993 THEN qty * product_price ELSE 0 END),
year5 = SUM(CASE WHEN sales_year = 1994 THEN qty * product_price ELSE 0 END),
totals = COALESCE(SUM(qty * product_price), 0)
FROM Sales AS S1
RIGHT OUTER JOIN Products AS P1
ON S1.product_name = P1.product_name
GROUP BY P1.product_name;
مراجع و اطلاعات بیشتر:
Advanced SQL Programming By Joe CELKO 3rd edition
Plamen Ratchev (SQL Server MVP)
|